This is a review note of the course TTIC 31230 Fundamentals of Deep Learning instructed by Prof. David McAllester.
Given two discrete distributions 

The cross entropy between them is

Given a fixed 


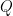
The answer is yes, and the reason is theoretical. First, we have to distinguish population and empirical distribution. Consider the problem of (English) language modeling, all the sentences in English form the population. We can never know the probability of any given sentence, as the number of possible sentences is infinity. However, we could take Wikipedia, or any other corpus, as a set of sampled sentences of the population, and assume that the sample is not biased (though it might not be always true). For a sentence (or any other instance) 




which is exactly what we computed by cross entropy loss, while

However, we are unable to know about 
From this perspective of view, it is worth noting that we are measuring 
