How do you like word embeddings? I’ve been asked this question a lot of times. In fact, I had a chance to ask Martha Palmer a similar question: How do you like deep learning? She specifically mentioned that she likes word embeddings, which improves almost all downstream tasks in the neural network era, and is somewhat interpretable.
Are word embeddings perfect? Definitely not. In this post, I’d like to share some thoughts and potential next steps derived from conversations with folks working on natural language processing, linguistics and cognitive science. If you’re curious about a comprehensive survey of word embeddings, I’d strongly recommend this one.
Learning word embeddings from corpus.
The basic idea of word embeddings is mapping a word to a d-dimensional vector, i.e., embedding a word to a d-dimensional space. Such an idea is based on the distributional hypothesis of semantics: words that are used and occur in the same contexts tend to purport similar meanings. There’re two popular approaches: continuous bag-of-words (CBoW) and skip gram.
Many folks explain the difference between CBoW and skip gram as “predicting a word given context” (CBoW) vs. “predicting context given a word” (skip gram). I’ve also seen some posts saying “the skip gram model is just a flipped CBoW model”. Well it’s somewhat true, but the skip gram part was a bit confusing to me five years ago — at that time, I was an undergrad whose knowledge about NLP is just tf-idf. I was especially confused by the following questions: “How can you predict the context? Generating them all? How do you do that? Different positions are not equivalent, then how do you deal with each position?”
I would highlight my own understanding to the difference between CBoW and skipgram as “predicting one given all” (CBoW) vs. “predicting one given one” (skip gram). Mathematically, the CBoW objective function is to maximize the overall probability of the observed word given the context:

where  represents the corresponding vector (embedding) of a specific word, and
represents the corresponding vector (embedding) of a specific word, and  represents a similarity metric between two vectors (larger means similar). Such similarity is usually measured by cosine, or negative Euclidean distance. Here, context is a set (bag) of words.
represents a similarity metric between two vectors (larger means similar). Such similarity is usually measured by cosine, or negative Euclidean distance. Here, context is a set (bag) of words.
As for skip gram, the goal of the objective function is not changed, but it instead model  for each context word respectively, assuming that each word in the context acts independently. Formally, the objective function becomes to maximize
for each context word respectively, assuming that each word in the context acts independently. Formally, the objective function becomes to maximize

Unfortunately, there exists a trivial solution to this optimization problem: all words share one vector, then the similarity is maximized. Mikolov et al. proposed to train skip-gram with negative sampling, which not only maximizes the probability of the true word given context, but also simultaneously minimizes that of the (randomly sampled) false word. The objective functions are

There’re also some efficient tricks on training skip gram, e.g., using different vector representations for main word or a context, smoothing the unigram distribution when sampling negative (false) words, etc.
Interpretability of word embeddings.
For each word, the corresponding vector, as a whole, represents a meaning. According to this fact, word embeddings can be intuitively interpreted by looking at each word’s nearest neighbors. The word “cat” often has a large similarity with “dog”, but probably a smaller similarity with “philosophy”.
Is there some direction in the vector space representing some concrete properties (e.g., “singular or plural”, “present or past”, “animal or not”, “soft or not”, etc.)? QVec by Yulia Tsvetkov et al. may serve as an example of understanding what happened inside the vectors, where they propose to align each dimension of word embeddings to predefined linguistic property. Nevertheless, word embeddings might not be compositional — each dimension might represent multiple things, and several dimensions might represent one thing together. One can probably try to probe the correlation between a direction (instead of a dimension) and a word property.
Multi-sense word embeddings and metaphors.
A word can have multiple senses. As an example, “bank” can be the slope beside a body of water, as well as a depository financial institution. It’s essential to have context to fully understand which sense it’s referring to. Researchers have developed mutli-sense word embeddings, which assigns each sense a separated vector.
For “supervised” multi-sense word embeddings, the model requires a labeled word sense resource (say, WordNet in English). It somehow matches each word in the corpus to a predefined sense, and train typical word embeddings based on the labeled corpus. For “unsupervised” multi-sense word embeddings, folks (Huang et al., Neelakantan et al., Li et al.; inter alia) use clustering or probabilistic clustering techniques to select the corresponding sense for each word in the corpus, where the sense selection model and the word embeddings can be jointly optimized.
The idea of multi-sense word embeddings is simple and intuitive. However, it’s unfortunately beaten by global word embeddings on almost all downstream tasks (e.g., sentiment analysis, text classification etc.). Moreover, the unsupervised approaches ignore metaphors. Metaphorical usages often appear in a different context from literal ones, but they do have the same sense — clustering based on context might mistakenly classify metaphorical usages (especially those typical ones) to different senses.
Contextualized word embeddings.
Before introducing contextualized word embeddings, I wanted to propose two mechanisms about how humans understand words in a context.
(1) word-> sense -> contextualized word meaning
(2) word -> contextualized word meaning.
I personally prefer the latter. A distant demonstration would be as follows. Consider the following sentences:
(1) Cats are cute.
(2) (You have two American shorthair cats.) Your cats are cute.
Both “cats” are with the same sense. We don’t have a concrete picture about which cat in our mind when seeing the first sentence, but we do have it when seeing the second one. We don’t firstly map “your cats” to a general concept “cats”, and then generate the picture; instead, such a picture immediately emerges when we see the sentence. I wished I could see some work in psychology or psycholinguistics about this issue, but I failed in searching for them. Any suggestion in the comments is welcomed.
The idea of contextualized word embeddings is to also encode contextual information into the word embeddings. Same word in different sentences might have different embeddings. Contextualized word embeddings can be hidden states of a recurrent neural network based language model, hidden states of a transformer based language model, or such hidden states of models targeting in any downstream tasks. Some popular contextualized word embeddings trained on huge corpus (ELMo, BERT, inter alia) has achieved amazing performance on a bunch of downstream tasks.
Cross-Lingual word embeddings.
I also wanted to mention cross lingual word embeddings, as parallel words/sentences in different languages provide free grounding signals in training and interpreting word embeddings.
One interesting approach is aligning word embeddings in different languages. Suppose we have trained word embeddings in two languages separately, and would like to align the two embedding spaces. With the assumption that the word distribution is similar across all languages, we can train a linear (or non-linear, but linear is simple and effective) transformation based on a small set of pivot words in the two languages. We can do even more crazy things (e.g., unsupervised word translation!) using cross-lingual word embeddings and unsupervised aligning techniques.
Bias from the corpus and downstream task.
We definitely don’t want race or gender stereotypes in the learned word embeddings — women can be computer programmers and men can be housemakers as well. However, almost all learned word embeddings, more or less, think women are more likely to be housemakers compared with men. Formally, such stereotype is reflected as follows

I have to emphasis this is an unwanted feature, but not a bug — such phenomenon meets the distributional hypothesis; the bias comes from the corpus itself but the word embedding methods. It’s also great to see folks working on debiasing word embeddings and more general machine learning models (Bolukbasi et al., 2016; Zhao et al., 2019; Sap et al., 2019; inter alia).
Quantifying attention on each word in a deep learning model.
This topic is worth another post — I just wanted to briefly mention it. Recently, I’ve seen lots of work apply the following attention mechanism. Let’s look at a typical supervised sentiment classifier as an example:
Given the words in a sentence, the model first maps each word to its word embedding  , and then pass them into a long-short term memory cell (LSTM) or a bidirectional LSTM to get the hidden states after seeing each word, denoted as
, and then pass them into a long-short term memory cell (LSTM) or a bidirectional LSTM to get the hidden states after seeing each word, denoted as  . Next, it computes “attention” based on the hidden states using a multi-layer perceptron (MLP) as follows
. Next, it computes “attention” based on the hidden states using a multi-layer perceptron (MLP) as follows

and combines all the hidden states to get a fixed-dimensional sentence representation

Finally, such representation is passed into another MLP for sentiment classification.
Is such attention interpretable? Do they reliably assign higher weights to those positions corresponding to important words to the downstream tasks? My answer is no, as it’s affected by the contextualized step a lot. While  only carries information from the i-th word,
only carries information from the i-th word,  actually carries the information from both the i-th word and its context. It doesn’t make sense to look at
actually carries the information from both the i-th word and its context. It doesn’t make sense to look at  to extract important words to downstream tasks.
to extract important words to downstream tasks.
How to extract such important words? I’d recommend looking at the L1/L2 norm of the Jacobian (and I’ve also done it in two of my papers(1, 2)!):

where  is the final loss value calculated from the input sentence and the gold label,
is the final loss value calculated from the input sentence and the gold label,  .
.  , in some sense, represents the importance of the i-th word. Here,
, in some sense, represents the importance of the i-th word. Here,  represents k-norm, where we usually use k=1 or 2.
represents k-norm, where we usually use k=1 or 2.
Beyond distributional hypothesis?
Antonyms can often appear in a similar context: For example, “The restaurant is nice.” vs. “The restaurant is terrible.” However, most word embeddings (even the contextualized ones) cannot capture “nice” and “terrible” here are antonyms. I’ve only seen models capturing such relation of sentiment-bearing words in sentiment classification, but there’s few work showing that other neutral antonyms (e.g., short vs. long/tall, thin vs. thick) can also be identified in an unsupervised way. I’d be definitely interested in seeing more work on this!
 scaling process in the multi-head attention mechanism.
scaling process in the multi-head attention mechanism.  denote the query vectors, the key matrix and the value matrix respectively. Given a query
denote the query vectors, the key matrix and the value matrix respectively. Given a query 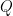 , the Transformers compute a weighted sum over all possible values by
, the Transformers compute a weighted sum over all possible values by 
 . The authors claim that such a scaling factor prevents the dot product from growing too large in magnitude so that we can have reasonable gradients through softmax—this makes a lot of sense, but the question is: why do the authors choose
. The authors claim that such a scaling factor prevents the dot product from growing too large in magnitude so that we can have reasonable gradients through softmax—this makes a lot of sense, but the question is: why do the authors choose  or
or  etc., to do the scaled multi-head attention?
etc., to do the scaled multi-head attention? . Assume that each dimension of either
. Assume that each dimension of either  or
or  is independently drawn from a zero-mean, unit-variance distribution. Recall that for independent random variables
is independently drawn from a zero-mean, unit-variance distribution. Recall that for independent random variables  , we have
, we have ![\begin{aligned} Var[XY] &= E[X^2Y^2] - E^2[XY] \\ &= (Cov[X^2, Y^2] + E[X^2]E[Y^2]) - (Cov[X,Y] + E[X]E[Y])^2 & ~~~~~(Cov[X,Y] = E[XY] - E[X]E[Y]) \\ &= E[X^2]E[Y^2] - E^2[X]E^2[Y] & ~~~~~(\text{the independence of } X, Y) \\ &= (Var[X] + E^2[X] )(Var[Y] + E^2[Y]) - E^2[X]E^2[Y] & ~~~~~(Var[X] = E[X^2] - E^2[X]) \\ &= Var[X]Var[Y] + Var[X]E^2[Y] + Var[Y]E^2[X] \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+Var%5BXY%5D+%26%3D+E%5BX%5E2Y%5E2%5D+-+E%5E2%5BXY%5D+%5C%5C+%26%3D+%28Cov%5BX%5E2%2C+Y%5E2%5D+%2B+E%5BX%5E2%5DE%5BY%5E2%5D%29+-+%28Cov%5BX%2CY%5D+%2B+E%5BX%5DE%5BY%5D%29%5E2++%26+%7E%7E%7E%7E%7E%28Cov%5BX%2CY%5D+%3D+E%5BXY%5D+-+E%5BX%5DE%5BY%5D%29+%5C%5C+%26%3D+E%5BX%5E2%5DE%5BY%5E2%5D+-+E%5E2%5BX%5DE%5E2%5BY%5D+%26+%7E%7E%7E%7E%7E%28%5Ctext%7Bthe+independence+of+%7D+X%2C+Y%29+%5C%5C+%26%3D+%28Var%5BX%5D+%2B+E%5E2%5BX%5D+%29%28Var%5BY%5D+%2B+E%5E2%5BY%5D%29+-+E%5E2%5BX%5DE%5E2%5BY%5D+%26+%7E%7E%7E%7E%7E%28Var%5BX%5D+%3D+E%5BX%5E2%5D+-+E%5E2%5BX%5D%29+%5C%5C+%26%3D+Var%5BX%5DVar%5BY%5D+%2B+Var%5BX%5DE%5E2%5BY%5D+%2B+Var%5BY%5DE%5E2%5BX%5D+%5Cend%7Baligned%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![Var[q_i] = Var[k_i] = 1](https://s0.wp.com/latex.php?latex=Var%5Bq_i%5D+%3D+Var%5Bk_i%5D+%3D+1&bg=ffffff&fg=000000&s=0&c=20201002) , and
, and ![E[q_i] = E[k_i] = 0](https://s0.wp.com/latex.php?latex=E%5Bq_i%5D+%3D+E%5Bk_i%5D+%3D+0&bg=ffffff&fg=000000&s=0&c=20201002) for any
for any  ,
, ![Var[q\cdot k] = \sum_{i=1}^{d_k} Var[q_i k_i] = d_k](https://s0.wp.com/latex.php?latex=Var%5Bq%5Ccdot+k%5D+%3D+%5Csum_%7Bi%3D1%7D%5E%7Bd_k%7D+Var%5Bq_i+k_i%5D+%3D+d_k+&bg=ffffff&fg=000000&s=0&c=20201002)
 by
by ![Var[\frac{q \cdot k}{\sqrt{d_k}}] = \sum_{i=1}^{d_k} Var[\frac{q_i k_i}{\sqrt{d_k}}] = \sum_{i=1}^{d_k} \frac{1}{d_k} Var[q_i k_i] = 1](https://s0.wp.com/latex.php?latex=Var%5B%5Cfrac%7Bq+%5Ccdot+k%7D%7B%5Csqrt%7Bd_k%7D%7D%5D+%3D+%5Csum_%7Bi%3D1%7D%5E%7Bd_k%7D+Var%5B%5Cfrac%7Bq_i+k_i%7D%7B%5Csqrt%7Bd_k%7D%7D%5D+%3D+%5Csum_%7Bi%3D1%7D%5E%7Bd_k%7D+%5Cfrac%7B1%7D%7Bd_k%7D+Var%5Bq_i+k_i%5D+%3D+1&bg=ffffff&fg=000000&s=0&c=20201002)
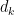 is.
is.  as close to the basic assumption (zero mean and unit variance) as possible. One may also want to consider
as close to the basic assumption (zero mean and unit variance) as possible. One may also want to consider  denote a vector, of which each element
denote a vector, of which each element  is independently drawn from a zero-mean and unit-variance distribution. We compute the output
is independently drawn from a zero-mean and unit-variance distribution. We compute the output  by
by 
 independently from the uniform distribution on the interval
independently from the uniform distribution on the interval  , which gives zero-mean and unit variance properties to
, which gives zero-mean and unit variance properties to 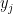 as well.
as well.  denote the probability for model
denote the probability for model  to generate pattern
to generate pattern  , the entropy of such distribution is
, the entropy of such distribution is



 , the
, the 

 , there is no difference between minimizing
, there is no difference between minimizing  and minimizing
and minimizing  to find an optimal
to find an optimal  , let
, let  denote the true probability of
denote the true probability of  denote the empirical probability of
denote the empirical probability of  denote the estimated probability of
denote the estimated probability of 

 .
.  instead of
instead of 